Vacuum là một tiến trình rất quan trọng, ảnh hưởng tới hiệu năng của nhiều dự án sử dụng Database PostgreSQL.
Trong các dự án mà tôi thực hiện tối ưu có sử dụng Database PostgreSQL, Vacuum là một yếu tố không thể không xem xét. Đây là một tiến trình đặc biệt quan trọng trong PostgreSQL và có nhiều ảnh hưởng tới hiệu năng. Bài viết này tôi sẽ chia sẻ với anh em những tư duy từ kiến trúc xem Vacuum bản chất nó là gì, vì sao cần tiến trình này, nó tác động thế nào tới Database.
1. Tại sao Vacuum tồn tại trong PostgreSQL ?
Tại sao các kỹ sư của PostgreSQL phải nghĩ ra Vacuum nhỉ ?
Để hiểu về Vacuum, chúng ta cần biết về kiến trúc MVCC của PostgreSQL trước đã.
Tôi tin rằng mọi công nghệ và giải pháp được lựa chọn trong kiến trúc phải nhằm giải quyết một bài toán rất cụ thể nào đó.
1.1. Kiến trúc MVCC (Multi-version concurrent control) của PostgreSQL
Hãy cùng xem bài toán mà PostgreSQL phải xử lý (thật ra đây là bài toán mà ông RDBMS nào cũng phải đối mặt luôn).
Thiết kế kiến trúc của Database làm sao để các dữ liệu ở trong đó có thể phục vụ đồng thời được đồng thời nhiều session cùng làm việc.
Tôi sẽ ví dụ cụ thể để anh em dễ hình dung
Giả sử tôi có Table lưu thông tin về số dư trong tài khoản của người dùng.
Tài khoản của tôi và vợ đang có 100$ trong đó.
Thời điểm 9h tôi dự định sẽ thực hiện rút 20$, tôi đã gõ lệnh UPDATE nhưng chưa hề COMMIT.
Sau đó 1 phút, tôi thực hiện SELECT giá trị của tài khoản của mình, kết quả mà tôi nhìn thấy ở SESSION của tôi sẽ là 100 - 20 = 80$.
Vợ tôi vào ở 1 session khác lúc này, cô ấy cũng SELECT tài khoản, nhưng ở SESSION này sẽ thấy giá trị trong tài khoản là 100$ (hiển nhiên, vì câu lệnh UPDATE chưa được COMMIT).
Vậy tại sao cùng 1 dữ liệu, nhưng chúng ta có thể thiết kế để đáp ứng được hành vi trên ?
- Người dùng nào đang trong session thay đổi dữ liệu sẽ nhìn thấy dữ liệu của họ được cập nhật
- Những người dùng ở session khác thì chỉ nhìn thấy dữ liệu sau khi đã COMMIT.
Ý tưởng để giải quyết bài toán này cũng không có gì quá khó cả.
Tại đây ta sẽ có 2 giá trị cần lưu đồng thời
- Giá trị của bản ghi bị thay đổi (trong ví dụ trên là 80$)
- Giá trị cũ (trước khi bị thực hiện thay đổi bởi câu lệnh Update - trong ví dụ trên là 100$).
Chúng ta chỉ cần lưu cả 2 giá trị này là xong.
Cách thiết kế để để lưu 2 giá trị này đồng thời thì mỗi Database sẽ có 1 hướng riêng:
- Với Oracle, họ thiết kế ra UNDO SEGMENT, đây là một nơi lưu giá trị khác biệt với Table chứa dữ liệu gốc
- Với SQL Server, họ cũng lưu riêng 2 dữ liệu ra 2 vùng khác nhau, ông này sử dụng TEMPDB
- Còn với PostgreSQL, ông này dùng lối đi riêng, sẽ lưu cả 2 dữ liệu ấy trên cùng Table gốc luôn. Tư tưởng sẽ là nó tạo ra các phiên bản khác nhau của dữ liệu (Version). Và kiến trúc này thường được biết tới với thuật ngữ MVCC (Multi-version concurrent control).
Đến đây chắc anh em hiểu về mặt tư tưởng rồi, tiếp theo tôi sẽ Demo trực tiếp để anh em nhìn thấy cách thật sự PostgreSQL lưu trữ Database theo phong cách “MVCC” thì thế nào nhé.
1.2. Demo kiểm tra dữ liệu trong PostgreSQL khi sử dụng kiến trúc MVCC
Chiến lược của Demo này như sau:
- Đầu tiên tôi sẽ tạo 1 Table chứ 10000 dữ liệu
- Sau đó thực hiện Update 50% số lượng bản ghi trong Table trên
- Trong quá trình này, tôi sẽ kiểm tra thông tin các bản ghi ấy được lưu trong Table như thế nào, tôi sẽ sử dụng cả các cột “ẩn” của hệ thống để anh em thấy được sự khác biệt giữa trước và sau khi thực hiện Update.
- Anh em cũng thấy được là sau khi Update, vì kiến trúc MVCC nên các bản ghi “mới” và bản ghi “cũ” cùng chứa trong Table ban đầu dẫn tới dung lượng của bảng tăng lên.
Chi tiết kịch bản, các số liệu dẫn chứng anh em sẽ cùng nhau thực hiện bên dưới nhé.
Bước 1: Tạo table phục vụ cho Demo
CREATE TABLE users_demo (
id SERIAL PRIMARY KEY,
full_name TEXT,
email TEXT,
age INT,
created_at TIMESTAMP DEFAULT now()
);
Bước 2: Insert 10.000 dữ liệu
INSERT INTO users_demo (full_name, email, age)
SELECT
'User ' || g,
'user' || g || '@wecommit.com',
20 + (random()*30)::INT
FROM generate_series(1, 10000) AS g;
Bước 3: Kiểm tra dữ liệu đã thêm vào
SELECT * FROM users_demo
Kết quả
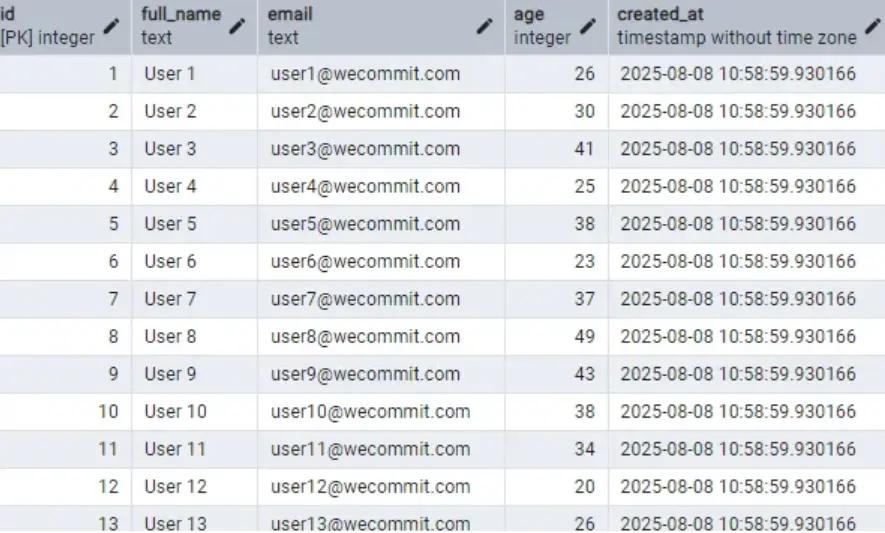
Bước 4: Kết quả mà anh em nhìn thấy bên trên chỉ là thứ mà người lập trình, những người dùng cuối chúng ta nhìn thôi. Thật ra PostgreSQL còn 1 số cột thông tin ảo, để sau này nó quản lý được “Multi-version” trong kiến trúc MVCC . Tôi sẽ cho anh em thấy thông tin ấy ngay bây giờ.
SELECT ctid, * FROM users_demo
Kết quả
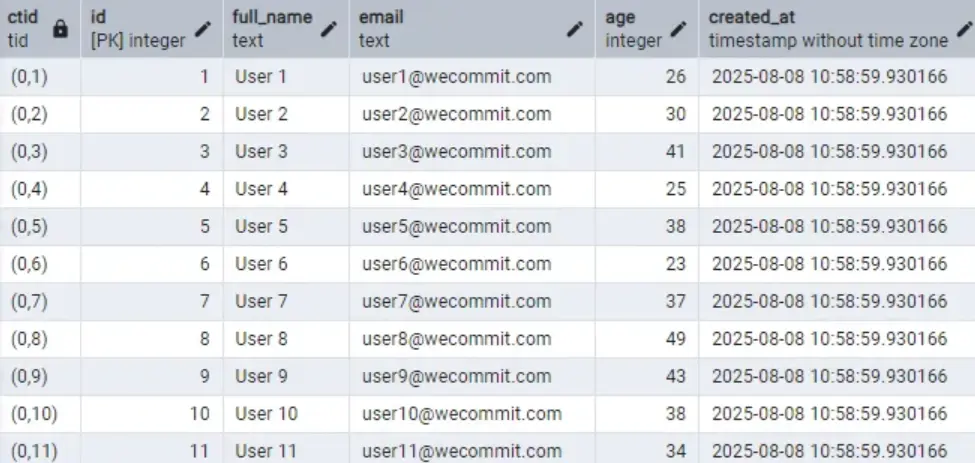
Cột CTID trong PostgreSQL dùng để lưu địa chỉ mức VẬT LÝ của các bản ghi.
CTID = (0,1) nghĩa là bản ghi đó ở vị trí
- Page ID = 0 (Page đầu tiên)
- Vị trí trong Page = 1
- Bản ghi này tương ứng trong dữ liệu là bản ghi có ID = 1, Email = user1@wecommit.com.vn
Trong PostgreSQL mỗi Page có dung lượng 8KB. Hết 8KB này thì nó sẽ tạo ra 1 Page mới để lưu tiếp dữ liệu.
Từ vị trí lưu mức vật lý, chúng ta cũng có thể kiểm tra ngược lại để biết giá trị dữ liệu nào đang lược lưu.
Chúng ta thử kiểm tra xem ở Page thứ 2 (Page_ID=1) và ở dòng đầu tiên thì giá trị đang lưu là gì nhé.
SELECT ctid, * FROM users_demo where ctid='(1,1)'
Kết quả

Bước 5: Kiểm tra dung lượng hiện tại của Table
SELECT
pg_size_pretty(pg_table_size('users_demo')) AS table_size
"792 kB"
Bước 6: Chúng ta chuẩn bị thấy sự xuất hiện của “Multi-version” các bản ghi (theo đúng lý thuyết của kiến trúc MVCC PostgreSQL) anh em nhá. Tôi sẽ thực hiện cập nhật trên Table này.
UPDATE users_demo
SET age=age + 1
WHERE id %2 = 0;
UPDATE 5000
Ở câu lệnh trên, tôi thực hiện cập nhật tất cả các bản ghi nào mà ID là chẵn. Và câu lệnh này đã thực hiện update trên 5000 bản ghi thỏa mãn.
Bây giờ anh em chú ý các phần kết quả bên dưới nhé
Bước 7: Thực hiện kiểm tra lại dữ liệu trên table xem PostgreSQL đang lưu thế nào
SELECT ctid, * FROM users_demo
Kết quả
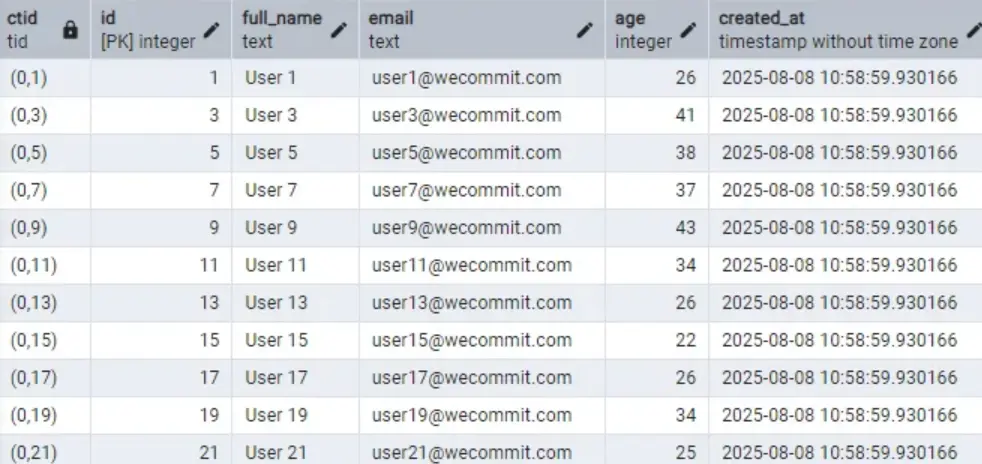
Một số điều nhận thấy nhanh ở đây
- Trong kết quả này hiện lên toàn thấy ID là số lẻ thôi, mấy cái ID là số chẵn chạy ở đâu mất rồi ?
- Các CTID của những ID có giá trị lẻ đang giữ nguyên so với ban đầu
Tôi sẽ đi tìm hiểu xem các ID là số chẵn bây giờ đang lưu lạc ở đâu trong Table khi PostgreSQL dụng theo kiến trúc MVCC nhé.
Bước 8: Kiểm tra các dữ liệu có ID nhận giá trị chẵn xem đang có CTID thế nào
SELECT ctid, * FROM users_demo where id % 2 = 0
Kết quả
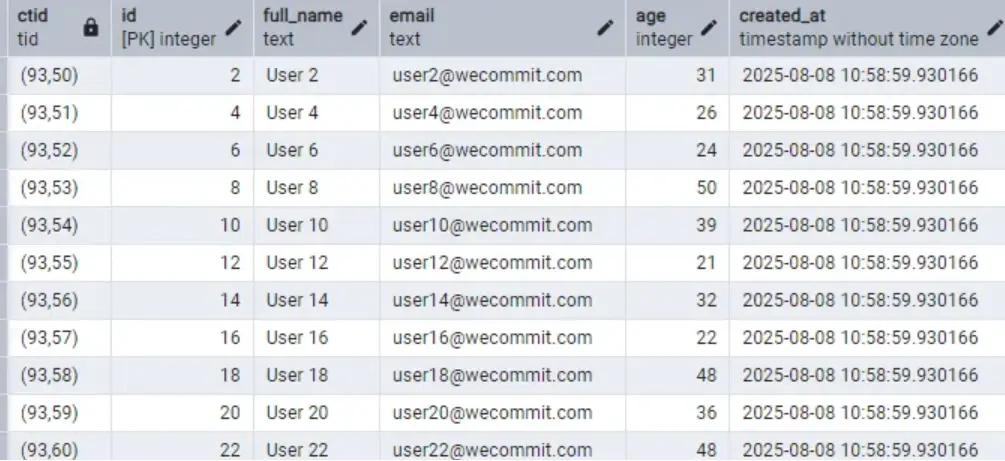
Nhận xét nhanh ở đây: Các bản ghi có CTID là giá trị chẵn đã bị chuyển ra các PAGE khác (và ở xa hơn nhiều so với ban đầu). Bản ghi có ID = 2 (Email là user2@wecommit.com.vn) đã chuyển từ CTID (0,2) ban đầu sang CTID (93,50).
PostgreSQL không cập nhật trực tiếp vào địa chỉ vật lý (CTID) cũ, thay vào đó nó sẽ tạo ra 1 phiên bản mới (theo tư tưởng Multi-version), phiên bản mới này sẽ được cấp ở 1 Page mới.
Vậy là đồng thời PostgreSQL sẽ phải lưu cả những dữ liệu ở địa chỉ cũ và ở cả địa chỉ mới.
Về logic anh em sẽ thấy là Table thật sự sẽ phải tăng trưởng nhiều về DUNG LƯỢNG mặc dù số lượng bản ghi không hề thay đổi.
Bước 9: Kiểm tra lại dung lượng của Table sau khi đã Update.
SELECT
pg_size_pretty(pg_table_size('users_demo')) AS table_size
"1168 kB"
Dung lượng bảng đã tăng từ 792 KB lên 1168 KB (tăng trưởng ~ 1.47 lần).
Dung lượng tăng lên thế này thì có ảnh hưởng hiệu năng khi các câu lệnh SQL thực hiện trên PostgreSQL không ?
Đáp án của câu trả lời này là có nhé anh em.
Có cách gì để xử lý được vấn đề hiệu năng này của kiến trúc MVCC trong PostgresQL không ?
Có cách. Các kỹ sư của PostgreSQL thiết kế ra 1 tiến trình để thực hiện việc “dọn dẹp” các bản ghi đã của các Version không còn sử dụng nữa (gọi là Dead Tuple). Tư duy thì giống như anh em mình vứt đồ bừa bộn, thì sẽ cần có 1 người đi quét nhà vậy.
Tiến trình đó chính là VACUUM.
2. Các loại Vacuum trong PostgreSQL
Để đọc chi tiết tài liệu thì trên Documents của PostgreSQL cũng có nhiều, anh em có thể xem tại link này.
Ở dưới đây tôi sẽ tóm gọn những ý quan trọng cho anh em đỡ mất thời gian tìm hiểu
2.1. Vacuum Full trên PostgreSQL
Ở trong Demo bên trên Table bị phân mảnh với số lượng blocks tăng gần gấp 1.5 lần.
Nếu chúng ta muốn dọn dẹp toàn bộ các Dead Tuple (những version cũ, không còn dùng nữa của các bản ghi) và thu hồi luôn cả phần dung lượng dư thừa của bảng, anh em có thể sử dụng Vacuum Full.
VACUUM FULL users_demo;
Sau câu lệnh này, chúng thực hiện kiểm tra lại dung lượng bảng xem sao nhé
SELECT
pg_size_pretty(pg_table_size('users_demo')) AS table_size
"760 kB"
Tôi không muốn chúng ta chỉ dừng lại là “ồ, dung lượng đã được thu hồi nhỏ lại”, chúng ta sẽ đi tìm hiểu cụ thể hơn ở đây.
Những dữ liệu trong bảng bây giờ được sắp xếp thế nào ?
Thực hiện kiểm tra việc lưu trữ dữ liệu trên table lúc này
SELECT ctid, * FROM users_demo
Kết quả
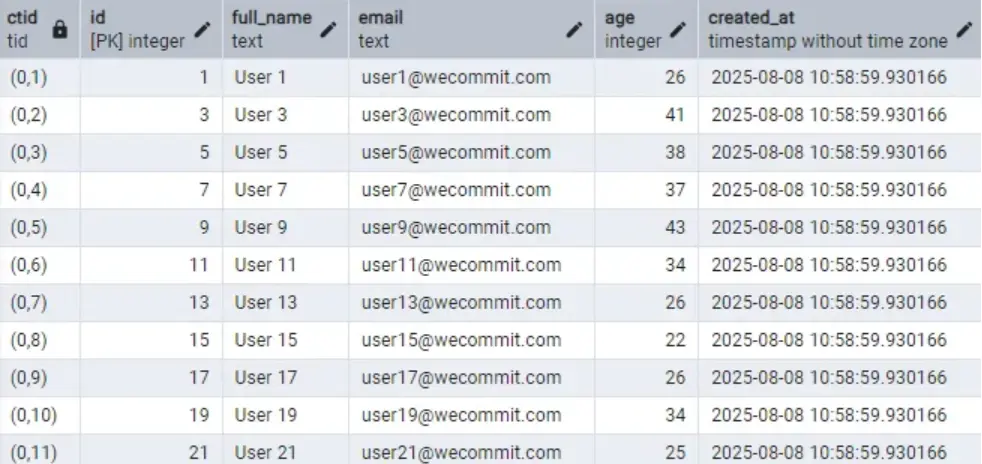
Hãy để ý những giá trị ở đây:
- Chúng ta thấy ngay một điều là các dữ liệu bây giờ đã được lưu trữ ở những ô địa chỉ vật lý liền nhau.
- Cụ thể: Trước đây User 3 (có email là user3@wecommit.com.vn) đang lưu ở CTID (0,3), đã được dịch chuyển xuống thành CTID (0,2).
Như vậy, câu lệnh VACUUM FULL của PostgreSQL đã thực hiện
- Bước 1: Giải phóng CTID (0,2) cũ đang lưu phiên bản của User 2 (trước khi bị câu lệnh UPDATE ảnh hưởng).
- Bước 2: thực hiền “dồn lại’ để các dữ liệu liền nhau liên tục.
VACUUM FULL mang lại hiệu quả triệt để về dung lượng lưu trữ, chống phân mảnh rất mạnh dữ liệu trong Table của PostgreSQL.
Tuy nhiên, khi anh em nhìn quy trình xử lý bên trên, có một thứ cần lưu ý
Khi thực hiện VACUUM FULL sẽ có LOCK trên Table, ảnh hưởng tới các tiến trình đang hoạt động lúc VACUUM thực hiện.
2.2. Auto Vacuum trên PostgreSQL
Bản thân PostgreSQL biết vấn đề của kiến trúc MVCC, do đó nó có tiến trình tự động thực hiện Vacuum. (Ghi chú: Anh em tìm theo thuật ngữ đúng thì tài liệu thường viết liền 2 từ Auto Vacuum thành autovacuum, nhưng tôi viết tách riêng để hiểu đúng ngữ nghĩa nhá).
Trong PostgreSQL, sẽ có 1 ngưỡng thể thể hiện mức độ ảnh hưởng “phân mảnh” của bảng, quá quá nhiều Dead Tuple.
Nếu tới ngưỡng này, PostgreSQL sẽ tự động thực hiện tiến trình Vacuum.
Tiến trình Auto Vacuum này khác với Vacuum Full mà chúng ta vừa được biết bên trên.
Mục tiêu chính của Auto Vacuum là dọn dẹp các “Version cũ”, không còn sử dụng nữa của các bản ghi, nhưng không cần phải thu hồi dung lượng (ở mức Pages/Blocks - mức vật lý).
Tiến trình Auto Vacuum xảy ra mà không yêu cầu PostgreSQL phải LOCK Table, do đó ít ảnh hưởng tới các câu lệnh đang thực hiện trên Table đó.
Tôi sẽ kiểm tra các thông số để thấy rõ hoạt động của Auto Vacuum như thế nào anh em nhé.
Đầu tiên là chu kỳ PostgreSQL sẽ đi kiểm tra các ngưỡng (kiểu như triggers ấy), nếu vượt ngưỡng thì gọi sẽ tự động thực hiện Vacuum.
show autovacuum_naptime;
1min
Kết quả này cho thấy: chu kỳ thực hiện là 60s / lần, cũng khá dày đặc đấy anh em.
Các ngưỡng quyết định thực hiện thì có thể xem bởi 2 câu lệnh sau
SHOW autovacuum_vacuum_threshold;
SHOW autovacuum_vacuum_scale_factor;
3. Những điều cần lưu ý về Vacuum
Dưới đây là những điều anh em ít để ý nhưng lại rất cần thiêt trong dự án.
- Trường hợp nào Vacuum thực hiện nhưng không xóa được các Dead Row/ Dead Tuple
- Những giới hạn của Vacuum trong PostgreSQL là gì ?
- Lưu ý đặc biệt liên quan tới sự khác biệt hiệu năng của Vacuum của PostgreSQL (trước và sau phiên bản PostgreSQL 17 có sự khác biệt gì ?)
Anh em có thể xem trong video giải mã về Vacuum PostgreSQL mà tôi từng làm nhé.
4. Tổng kết & những tài liệu tham khảo
Chốt hạ lại thì Vacuum là một trong các tiến trình quan trọng bậc nhất, cốt lõi trong PostgreSQL.
Không có nó hoặc nó bị treo thì Database của anh em sớm muộn cũng sẽ “chậm”, “cực chậm”, và phình to vô tội vạ.
Một số Keyword quan trọng anh em có thể mang đi sau khi đọc bài này:

Nếu anh em đang tìm hiểu về tối ưu Database, tối ưu SQL thì đây là một số tài nguyên, tài liệu anh em có thể xem
- Bài viết về tối ưu SQL nên bắt đầu từ đâu: click vào đây
- Bài viết về trường hợp câu lệnh SQL có hiệu năng thất thường (đây là thứ hay phải xử lý trong dự án OLTP thực tế): click vào đây
- Xem về Framework tối ưu mà tôi đang áp dụng trong các dự án. Đây là cách tăng công lực rất nhanh chóng cho anh em. Click vào đây