Tối ưu SQL đúng cách bắt buộc phải dùng góc nhìn kiến trúc, không chỉ là viết lại câu lệnh
Anh em lập trình chúng ta đôi khi cứ nghĩ rằng tối ưu SQL chỉ là một vài mẹo, trick lỏ gì đấy.
Có bác nghĩ tối ưu là thêm Index, viết lại câu lệnh, nâng cấp phần cứng, đơn giản ấy mà.
Nhưng tất cả những thứ đó chỉ là bề nổi, bài viết này chia sẻ một tình huống thực tế, và nó có thể giúp anh em một góc nhìn hoàn toàn mới trong vấn đề tối ưu hiệu năng Database cũng như tối ưu sql.
Anh em nghĩ sao nếu tôi thực hiện cùng 1 câu lệnh SQL, trên cùng một môi trường, với các đầu vào giống hệt nhau, liệu rằng hiệu năng câu lệnh này có luôn nhanh giống nhau không ?
Ý của tôi cùng môi trường nghĩa là
- Cùng làm việc với 1 Table
- Table đó giữ nguyên số cột, số bản ghi, chẳng thay đổi gì cả
- Table hoàn toàn bình thường, không bị corrupt hay phân mảnh gì hết.
- Cùng sử dụng 1 Database (cùng loại cơ sở dữ liệu, cùng cấu hình tham số, cùng phiên bản).
- Cùng phần cứng (RAM, CPU, tốc độ I/O các kiểu như nhau hết).
- Tải của hệ thống, số lượng connection không khác gì nhau cả
- Câu lệnh giống y xì nhau
Trên các dự án mà tôi phải xử lý, hiệu năng của cùng câu lệnh, với các thông tin bên trên, nhưng vẫn có thể xảy ra việc 1 thời điểm rất nhanh, một thời điểm thì rất chậm.
Tất cả những góc nhìn “ở phần bề nổi”, góc nhìn của người viết ra câu lệnh sẽ không thể giải thích được vì sao lại xảy ra hiện tượng trên.
Mà khi đã không giải thích được, thì chúng ta sẽ đổ hết cho “tâm linh”, ông nào triển khai quên không rửa tay rồi, thằng nào đầu tháng đã ăn vịt, đen quá.
Tôi sẽ gửi cả kịch bản, có cả scripts, câu lệnh để anh em tự mình kiểm chứng nếu muốn nhé.
Bây giờ chúng ta sẽ bắt đầu tìm hiểu những góc nhìn về bản chất của tối ưu sql nhé.
1. Demo tối ưu SQL trên SQL Server: Cùng một câu lệnh, hiệu năng khác biệt 120 lần.
Tôi quyết định lựa chọn một Database cũng đủ tên tuổi, câu lệnh không cần phức tạp gì cả để anh em hiểu nội dung một cách triệt để nhất (trong thực tế câu lệnh phức tạp hơn thì càng dễ dính chưởng hơn nữa).
1.1. Thông tin môi trường: Database SQL Server và bảng Users
Kịch bản của tôi được thực hiện trên cùng 1 Database, cùng 1 máy chủ luôn, anh em không phải băn khoăn là môi trường, cấu hình có khác gì nhau không
- Thông tin phiên bản SQL Server trong demo này
select @@VERSION
Microsoft SQL Server 2019 (RTM) - 15.0.2000.5 (X64) Sep 24 2019 13:48:23 Copyright (C) 2019 Microsoft Corporation Developer Edition (64-bit) on Windows Server 2019 Standard 10.0 <X64> (Build 17763: ) (Hypervisor)
Câu lệnh trong Demo sẽ thực hiện tương tác với một bảng Users duy nhất.
- Các thông số cần thiết liên quan tới Table này có thể xem trong mindmap dưới đây, bao gồm
- Cấu trúc của Table
- Thông tin Index
- Số lượng bản ghi
- Dung lượng lưu trữ trên storage
Tiếp theo, tôi sẽ tạo 1 Procedure để làm việc với Table Users trong môi trường nói trên.
1.2. Tạo Stored Procedure thử nghiệm
Thủ tục này chưa cần gì phức tạp cả, nó đơn giản là tìm các thông tin của người dùng (trong bảng Users) mà người đó có giá trị UpVotes bằng với tham số mà chúng ta truyền vào.
Anh em lưu ý là cột UpVotes đã có Index rồi nhé.
Đây là chi tiết câu lệnh tạo Procedure
CREATE OR ALTER PROCEDURE sp_get_users_by_upvotes
@upvotes INT
AS
BEGIN
SELECT *
FROM users
WHERE upvotes = @upvotes;
END;
Câu lệnh lệnh sau đây là “nhân vật chính” sẽ có sự chênh lệch hiệu năng hàng trăm lần mà tôi muốn anh em tập trung phân tích trong bài viết này.
EXEC sp_get_users_by_upvotes @upvotes = 0;
Câu lệnh này đơn giản chỉ là chạy Procedure vừa tạo với tham số truyền vào UpVotes =0, bản chất là tôi muốn tìm tất cả các ông Users mà cột UpVotes = 0.
Trong bảng Users có 1.782.780 (trên tổng số 2.465.713 bản ghi) bản ghi thỏa mãn điều kiện tìm kiếm trên.
select count(*) from Users where UpVotes = 0
1782780
Để đo lường chính xác hiệu năng của câu lệnh trên Database SQL Server, tôi sẽ thực hiện câu lệnh sau để lưu lại thông số chi tiết tài nguyên câu lệnh đang sử dụng.
Đây là câu lệnh tôi rất thường xuyên sử dụng trong các dự án tối ưu với SQL Server, đặc biệt để so sánh hiệu năng giữa các câu lệnh SQL trước và sau khi tối ưu. Anh em có thể ứng dụng vào dự án của mình nhé.
SET STATISTICS IO ON;
1.3. Kết quả Demo: Cùng truy vấn SQL, nhưng chênh lệch hiệu năng hơn 100 lần
Lưu ý, anh em muốn có các thông số hiệu năng như tôi đang demo dưới đây thì nhớ thực hiện lệnh sau:
SET STATISTICS IO ON;
Và sau đó, tôi thực hiện cùng câu lệnh thực thi Procedure sp_get_users_by_upvotes ở 2 thời điểm khác nhau, trên cùng một môi trường như đã nói và thấy rằng “hiệu năng chênh lệch nhau quá lớn”.
Lần đầu tiên thực hiện câu lệnh này
EXEC sp_get_users_by_upvotes @upvotes = 0;
(1782780 rows affected)
Table 'Users'. Scan count 1, logical reads 44530, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 25, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0
Hệ thống ghi nhận câu lệnh trên trả ra hơn 1.7 triệu bản ghi (cụ thể là 1.782.780 bản ghi), để thực hiện việc này thì hệ thống đã phải quét 44.530 page dữ liệu (thể hiện ở phần logical reads = 44530).
Một page dữ liệu của SQL Server có dung lượng là 8KB.
Như vậy, câu lệnh này đã phải thực hiện quét số lượng dữ liệu thực tế là 8KB * 44530 /1024 = 347 MB
Phần dung lượng 347 MB này cũng chính là dung lượng dữ liệu của toàn bộ bảng Users đang chiếm trên ổ cứng (anh em có thể xem lại phần thông số trong mindmap mà tôi có đưa trong phần thông tin môi trường phía bên trên).
Nói cách khác, câu lệnh này đã quét toàn bộ dung lượng (khoảng không gian mà table Users chiếm trên ổ cứng để tìm được các kết quả phù hợp).
Ở lần thực hiện thứ 2, cũng cùng câu lệnh SQL ấy, trên cùng hệ thống, tập dữ liệu, nhưng tôi lại thấy hiệu năng câu lệnh khác hoàn toàn
EXEC sp_get_users_by_upvotes @upvotes = 0;
(1782780 rows affected)
Table 'Users'. Scan count 1, logical reads 5351434, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 25, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Số lượng bản ghi trả ra vẫn không khác gì (cũng là 1782780), nhưng lúc này tài nguyên để thực hiện đã tăng lên 120 lần (logical reads bây giờ là 5351434 so với trước đây chỉ là 44530)
Và một điều kỳ lạ ở đây là: Toàn bộ dung lượng của bảng chỉ có 347MB, câu lệnh SQL chỉ làm việc trên mỗi bảng đó, tại sao hệ thống phải thực hiện số lượng đọc gấp hàng trăm lần như vậy ?
Điều gì đã xảy ra ở giữa 2 lần Demo ấy, tại sao hiệu năng của cùng một câu lệnh SQL, trên cùng một môi trường mà lại có sự không ổn định như vậy ?
Tôi sẽ cùng anh em phân tích chi tiết hơn ở phần sau nhé.
2. Khi hiệu năng SQL thay đổi, hãy kiểm tra ngay Execution Plan (chiến lược thực thi của SQL)
Luồng tư duy ở đây mà tôi muốn chia sẻ với anh em khi gặp sự bất ổn trong hiệu năng SQL đó là: kiểm tra ngay chiến lược thực thi của câu lệnh đó (hay thuật ngữ anh em sẽ thấy gọi là SQL Execution Plan).
Chiến lược thực thi của SQL cũng giống như tấm bản đồ để Database cần phải đi, để hoàn thành mục tiêu của của câu lệnh.
Không phải đi kiểm tra Index, cấu hình gì hết, mà ngay lập tức phải xem liệu Database có đang lựa chọn các con đường khác nhau hay không (chiến lược thực thi - Execution Plan bị thay đổi).
2.1. Kiểm tra Execution Plan: Chiến lược thực thi thực tế của 2 lần chạy câu lệnh SQL
Tôi kiểm tra chi tiết chiến lược thực thi của câu lệnh SQL trong 2 lần thực hiện, thì kết quả như sau
Đối với lần thực hiện đầu tiên (khi câu lệnh thực hiện nhanh). Chiến lược thực thi của SQL Server lựa chọn là quét toàn bộ Table Users, sau đó lọc ra kết quả thỏa mãn điều kiện UpVotes bằng 0.
Kiểm tra chiến lược thực thi thì anh em sẽ thấy như sau.
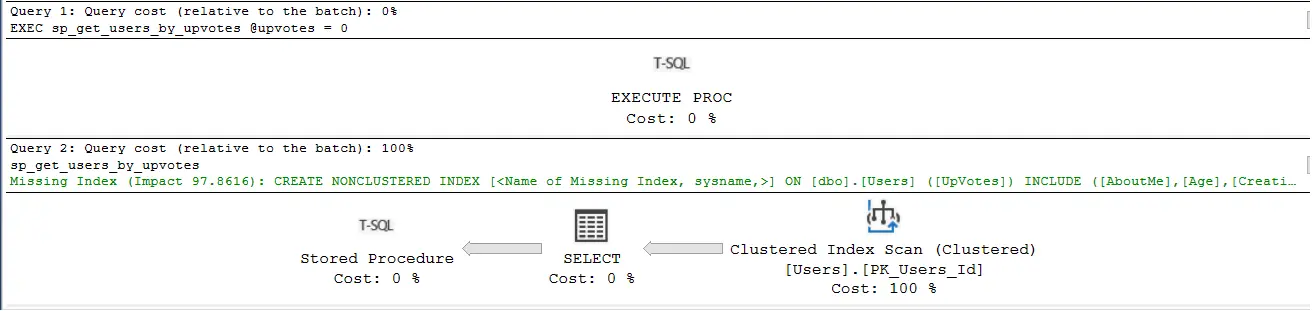
Ghi chú: Trong SQL Server thì Clustered Index chính là toàn bộ cái Table, nhưng dữ liệu được sắp xếp theo chiều tăng dần của cột đánh Index. Do đó Clustered Index Scan bản chất là Full Table Scan (quét toàn bộ bảng)
Nếu muốn xem chi tiết hơn, xem SQL Server sau khi quét toàn bộ Table đó thì làm gì, anh em có thể click chuột phải vào bước Clustered Index Scan và chọn Properties
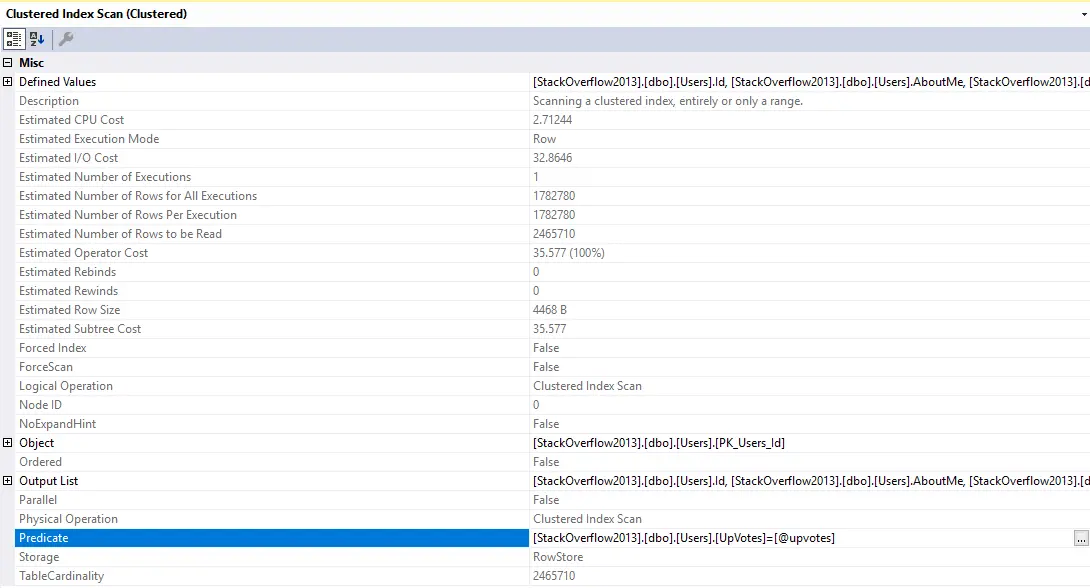
Phần thông tin này cho biết SQL Server sau khi đã quét toàn bộ dữ liệu của Table Users, nó sẽ thực hiện lọc ra tất cả các bản ghi có cột Upovtes bằng với giá trị tham số truyền vào. Điều này thể hiện ở mục Predicate:
Predicate: [Stackoverflow2013].[dbo].[Users].[Upvotes]=[@upvotes]
→ Chiến lược này hoàn toàn trùng khớp và logic với việc câu lệnh lúc đầu phải quét 347MB dữ liệu (đây chính là dung lượng của toàn bộ bảng Users).
Bây giờ tôi sẽ đi tìm hiểu xem, câu lệnh lần thứ 2 khi thực hiện, tại sao mà nó lại phải xử lý lượng dữ liệu lớn gấp hơn 100 lần như vậy.
Đây là chi tiết chiến lược thực thi của câu lệnh lúc đó
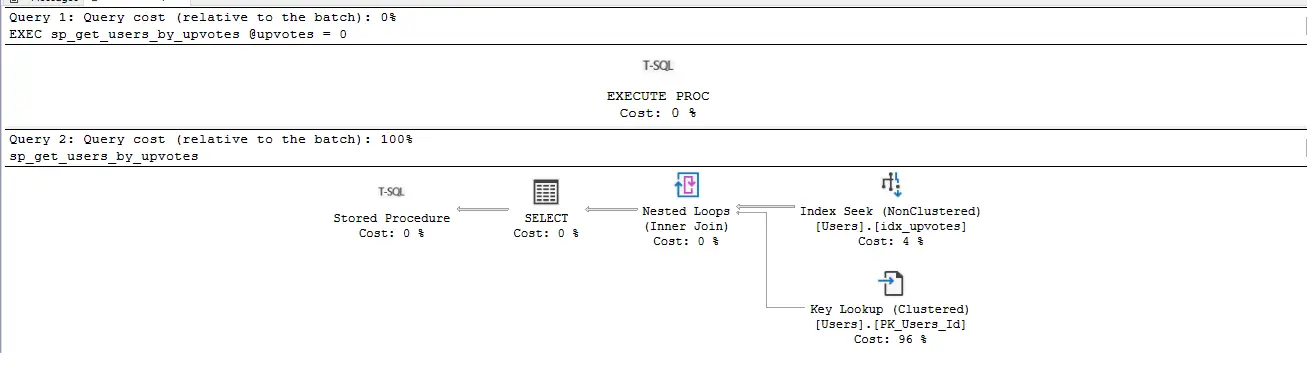
Anh em thấy rằng chiến lược thực thi của 2 câu lệnh này khác hẳn nhau.
Đây chính là lý do tại sao hiệu năng lại chênh lệch đến thế.
Bây giờ tôi sẽ phân tích sâu hơn vào chiến lược thực thi của câu lệnh SQL bị chậm.
Khi nhìn vào chiến lược thực thi của lần chạy thứ 2, chúng ta sẽ cần phải lưu ý một số điểm nổi bật
- Thứ nhất: SQL Server lúc này đã sử dụng Index trên cột UpVotes, thay vì quét toàn bộ bảng. Yeah, nhiều anh em cứ nghe thấy Index là tưởng ngon. Nếu thế thì xin chia buồn, chính vì cái việc sử dụng Index này mà làm câu lệnh lâu vỡ mẹt đấy anh em ạ.
- Thứ hai: Cái bước chiếm 96% hiệu năng (tức là thứ làm chậm nhất) là bước Key Lookup.
Bây giờ là giải thuật, khi phiên dịch từ Execution Plan thành ngôn ngữ của chúng ta
Bước 1: Database sẽ truy cập vào Index IDX_UPVOTES (đây chính là bước Index Seek NonClustered trong chiến lược thực thi). Tại bước này, SQL Server sẽ lọc ra tất cả những giá trị thỏa mãn điều kiện của người dùng UpVotes = 0.
Bước 2: Với mỗi thông tin tìm được ở bước 1, hệ thống thực hiện giải thuật Nested Loop. Bản chất của cái chỗ này chinh là nó chạy một vòng lặp For. Vòng lặp này sẽ đi tới bảng Users và mang các cột còn lại (mà cái Index kia không lưu, ví dụ như cột AboutMe, Age, Views).
Và hành động cứ nhảy từ Index rồi vào Table để tìm cột khác nó thể hiện ở từ khóa KeyLookup trong chiến lược thực thi anh em nhé.
Giải thuật này tệ vô cùng vì ở bước 1 gần như phần lớn các thông tin trong Index là thỏa mãn giá trị UpVotes = 0.
Vì sao ư ?
Anh em có còn nhớ rằng bảng Users chỉ có hơn 2.4 triệu bản ghi, và số lượng bản ghi thỏa mãn cái điều kiện kia là hơn 1.7 triệu không ?
Chính cái việc cứ quét rất nhiều Index, rồi mỗi giá trị ấy lại nhảy vào Table gốc (KeyLookup) nó đã kiến khối lượng dữ liệu phải quét của SQL Server tăng vọt lên 120 lần.
2.2. Tại sao chiến lược thực thi của câu lệnh SQL lại bị thay đổi ?
Đây là trường hợp rất kinh điển khi anh em đi tối ưu SQL, đặc biệt là tối ưu cho các cơ sở dữ liệu hệ thống OLTP.
Nếu như trong quá trình hoạt động, Database đã xóa chiến lược thực thi của câu lệnh lưu trên Memory (vì nhiều lý do khác nhau, có thể là bị flush cache, có thể do lâu không sử dụng nên hệ thống loại bỏ), sau đó có 1 người gọi thủ tục trên, nhưng với tham số hoàn toàn khác.
EXEC sp_get_users_by_upvotes @upvotes = 934;
(26 rows affected)
Lưu ý là thủ tục này chỉ trả ra 26 bản ghi thỏa mãn điều kiện lọc giá trị UpVotes=934.
Đối với số lượng bản ghi ít như vậy, hệ thống lựa chọn chiến lược thực thi là quét Index trên UpVotes (giải thuật hoàn toàn hợp lý khi số lượng bản ghi thỏa mãn là chiếm số % nhỏ trong Table).
Và sau đó ..
Một thời gian sau thì câu lệnh mà chúng ta nhắc tới trong Demo này mới được thực hiện (câu lệnh tìm kiếm UpVotes với giá trị 0).
Thời điểm này SQL Server phát hiện đã có 1 chiến lược thực thi được lưu trước đó khi thực hiện Procedure sp_get_users_by_upvotes rồi. Theo “bản năng”, SQL Server nghĩ là “ngon quá, lấy trong cache luôn thôi”.
Chính vì thế, nó lấy luôn chiến lược thực thi dùng Index.
Nhưng cuộc đời không như mơ, đối với câu lệnh tìm kiếm UpVotes bằng 0, số lượng giá trị thỏa mãn lại chiếm đại đa số trong Table Users, khác hoàn toàn so với việc chỉ có 26 bản ghi thỏa mãn khi tìm theo giá trị 934.
Chính vì vậy, chiến lược thực thi của câu lệnh SQL lúc này trở thành thảm họa.
Hiệu năng của câu lệnh SQL tệ hơn hàng trăm lần.
2.3. Video phân tích toàn bộ tình huống tối ưu SQL và demo thực tế trên SQL Server
Dành cho anh em nào theo phong cách muốn trực tiếp nhìn thấy Demo, không thích đọc dạng text.
Tôi có làm cả video phân tích luôn, anh em xem tại đây nhé
3. Kết luận & Góc nhìn Wecommit: Vì sao tối ưu SQL không đơn giản chỉ là viết câu lệnh hay tips, tricks
Từ demo trong bài viết này, có một vài điều mà anh em có thể thấy ngay, và cũng là lý do tại sao việc tối ưu SQL cần một góc nhìn sâu sắc hơn:
Không phải cứ có Index thì nhanh.
Trong trường hợp này, chính việc chiến lược thực thi của câu lệnh SQL dùng Index lại khiến hệ thống tiêu tốn tài nguyên hơn 120 lần.
Dữ liệu nhỏ nhưng vẫn có thể gây treo hệ thống
Bảng Users chỉ vài trăm MB, nhưng một sai lệch nhỏ trong cách SQL được thực thi có thể khiến hệ thống phải xử lý tới hàng chục GB. Đây không phải chuyện hiếm gặp, mà là thứ đã xảy ra nhiều lần trên các dự án thực tế, tôi đã xử rất nhiều vụ kiểu này rồi.
Tối ưu không nằm ở câu lệnh, mà nằm ở kiến trúc.
Muốn thật sự tối ưu Database, anh em phải nhìn câu lệnh dưới góc nhìn của Database, tức là góc nhìn của kiến trúc, phải hiểu tường tận khi một câu lệnh SQL gửi tới nó thực hiện các bước nào, trường hợp nào nó sẽ dùng cache, trường hợp nào không …
Nếu mãi nhìn dưới góc độ người viết ra câu lệnh, thì sẽ không thể lý giải vấn đề trong bài viết này và rất nhiều vấn đề khác nữa trong thực tế. Mà đã không lý giải được thì chẳng thể xử lý được
Nếu bạn muốn tìm hiểu tối ưu SQL thì nên bắt đầu làm/ học từ đâu, hãy xem một bài viết mà tôi từng chia sẻ: Click vào đây
Nếu bạn muốn thấy Framework tối ưu mà tôi đang trực tiếp áp dụng trong các dự án, bạn có thể xem và đăng ký trải nghiệm, xem tại đây: Xem chi tiết Framework Wecommit 100x