Buổi trưa thứ 5, trong lịch trình chia sẻ và tư vấn hàng tuần trên các dự án thực tế cùng các anh em trong Wecommit 100x, một học viên của tôi phân tích tình huống đang gặp:
Database trong dự án vừa thực hiện nâng cấp từ MySQL 5.7 lên MySQL 8.0.x thì thấy hiệu năng cải thiện rõ rệt, mặc dù chưa có bất kỳ thay đổi nào từ thiết kế (ví dụ: không bổ sung bất kỳ Index nào), không viết lại bất kỳ procedure, câu lệnh SQL nào hết.
Bài viết này tôi sẽ chia sẻ với anh em gốc rễ trong hiệu năng của Cơ sở dữ liệu MySQL 8, điều gì đã thay đổi hiệu năng của câu lệnh SQL mà anh em Dev chưa cần “động chân”, “động tay” gì hết.
1. Query Optimizer - bộ não quan trọng quyết định hiệu năng trong MySQL
Khi anh em Dev chúng ta gửi 1 câu lệnh SQL tới Database MySQL, làm thế nào mà ông MySQL này có thể thực hiện được yêu cầu ấy, lấy đúng các bản ghi mà chúng ta muốn ?
Làm sao mà MySQL biết có nên sử dụng Index hay không ?
Làm sao MySQL biết nên truy cập các Table trong câu lệnh SQL theo thứ tự nào (nếu câu lệnh dài, có subquery, join, where tùm lum) ?
Thứ đứng ra giải quyết mọi vấn đề trên chính là Query Optimizer.
Nói một cách đơn giản thì anh em có thể tượng tưởng nó giống như cái ứng dụng Google Map trong điện thoại vậy.
Câu lệnh SQL của chúng ta gửi tới là một yêu cầu: tôi muốn tìm đường đi từ nhà tới công ty, ông muốn tìm đường nào thì tìm, miễn là tôi đi tới đích.
Ông Google Map sẽ thực hiện nhiệm vụ của mình là đánh giá tất cả các phương án có thể có và chọn ra con đường ngắn nhất (mà theo nó nghĩ).
Query Optimizer làm nhiệm vụ đúng như vậy: nó phải hiểu được có bao nhiêu phương án có thể thực hiện được câu lệnh, những phương án này về thuật ngữ gọi là “chiến lược thực thi” (hay tên anh em có thể thấy trong các tài liệu là sql execution plan). Cuối cùng thì Query Optimizer sẽ chọn ra 1 chiến lược thực thi “ngon nhất” (ít tốn tài nguyên nhất) để thực hiện.
Chỗ này anh em có thể có câu hỏi:
Vậy Query Optimizer này có ở các database khác không nhỉ ?
Trả lời: Nó tồn tại ở mọi Database, từ Oracle, SQL Server, PostgreSQL đến các NoSQL như MongoDB. Và khi lựa chọn Database, thì đây là một yếu tố khác nhau vô cùng quan trọng mà những người làm chuyên sâu sẽ xét tới.
Việc khi chúng ta nâng cấp phiên bản MySQL 5.7 lên MySQL 8.0.x trong bài toán mà học viên tôi gặp phải bên trên, gốc rễ cũng là do Query Optimizer được cải tiến nên hiệu năng của một số câu lệnh được cải thiện mà chưa cần phải thực hiện thay đổi bất kỳ thứ gì từ phía lập trình viên.
1.1. Cách xem chiến lược thực thi của câu lệnh SQL trong MySQL
Chiến lược thực thi là “đầu ra” của Query Optimizer, và nó cũng là yếu tố ảnh hưởng lớn tới tốc độ của câu lệnh SQL.
Khi tối ưu trong dự án, tôi luôn có bước kiểm tra xem câu lệnh SQL mà khách hàng bị chậm, xem nó đang sử dụng chiến lược thực thi như thế nào.
Ghi chú: đây là cách tôi áp dụng với mọi Database (Oracle, PostgreSQL, SQL Server…) chứ không phải chỉ riêng cho Database MySQL.
Nhiều anh em Dev hay bị một chỗ “nhầm nhọt rất nguy hiểm” chỗ này: chỉ xem chiến lược thực thi sử dụng EXPLAIN.
Nếu anh em đọc các tài liệu sẽ thấy người ta nói rằng: sử dụng EXPLAIN + CÂU LỆNH SQL để xem chiến lược thực thi.
Điều này ĐÚNG, nhưng để ĐỦ, chúng ta cần biết rằng cái cú pháp EXPLAIN kia nó chỉ xem chiến lược thực thi DỰ KIẾN của câu lệnh mà thôi.
Về mặt đa số các trường hợp anh em sẽ thấy cái chiến lược thực thi dự kiến giống với chiến lược thực thi thực tế sử dụng, nhưng có nhiều bài toán tôi trực tiếp xử lý thì hiệu năng 2 ông này rất khác nhau.
Tôi chỉ muốn anh em lưu ý điểm này ở đây. Anh em có thể xem 1 video mà tôi có demo, phân tích nếu cần nhé: Click vào xem demo chiến lược thực thi của câu lệnh SQL thay đổi →
Để xem chiến lược thực thi DỰ KIẾN trong MySQL
explain select * from users where reputation = 400 and upvotes > 1
Kết quả
+----+-------------+-------+------------+-------+-----------------------+-----------------------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+-----------------------+-----------------------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | users | NULL | range | idx_reputation_upvote | idx_reputation_upvote | 8 | NULL | 396 | 100.00 | Using index condition |
+----+-------------+-------+------------+-------+-----------------------+-----------------------+---------+------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
Giải thích ý nghĩa của chiến lược này:
- ID =1 và select_type = SIMPLE → MySQL nhìn thấy đây là 1 câu lệnh rất đơn giản, không có join, subquery
- table = users → Cho biết tên của Table mà câu lệnh sẽ phải truy cập
- type = range → Cho biết giải thuật khi tìm kiếm dữ liệu trên Table này: MySQL sẽ sử dụng việc giải thuật gọi là RANGE SCAN
- possible_keys = idx_reputation_upvote → Query Optimizer cho rằng có thể sử dụng Index tên là idx_reputation_upvote để thực hiện câu lệnh SELECT này.
- key = idx_reputation_upvote → Query Optimizer của MySQL đã quyết định chọn Index idx_reputation_upvote
- key_len = 8 → Cho ta biết độ dài của phần Index mà MySQL dùng để so sánh là 8 Bytes
- ref = NULL → Câu lệnh này không có giá trị nào để đem Join với bảng khác cả (hiển nhiên vì câu lệnh này không có Join mà)
- rows = 396 → MySQL Query Optimizer ước lượng rằng có khoảng 396 bản ghi cần phải đọc trên Index
- filtered = 100.00 → MySQL đoán rằng 100% của 396 rows bên trên đều thỏa mãn điều kiện lọc
- Extra = Using index condition → Thông tin này cho biết MySQL đã sử dụng lọc ngay trên Index
KHOANNNNNNNNNNNNNNNNNN
Lúc nãy chúng ta vừa nói rằng: Query Optimizer trong MySQL sẽ chọn ra các chiến lược thực thi mà SỬ DỤNG ÍT TÀI NGUYÊN NHẤT.
Trong cái kết quả bên trên, chúng ta chẳng thấy chỗ nào thể hiện cái việc “ÍT TÀI NGUYÊN” cả !!!!!!
Làm thế nào mà chúng ta có thể xem được chính xác thì cái chiến lược thực thi ấy thì MySQL đang nhìn nó sử dụng tài nguyên thế nào (hay còn gọi là COST của câu lệnh SQL) ?
Trong MySQL thì anh em sử dụng EXPLAIN FORMAT=JSON hoặc EXPLAIN FORMAT=TREE để biết được thông tin này nhé
Nếu sử dụng FORMAT JSON sẽ ra như sau
mysql> EXPLAIN FORMAT=JSON select * from users where reputation = 400 and upvotes > 1;
| EXPLAIN |
| {
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "419.37"
},
"table": {
"table_name": "users",
"access_type": "range",
"possible_keys": [
"idx_reputation_upvote"
],
"key": "idx_reputation_upvote",
"used_key_parts": [
"Reputation",
"UpVotes"
],
"key_length": "8",
"rows_examined_per_scan": 396,
"rows_produced_per_join": 396,
"filtered": "100.00",
"index_condition": "((`stackoverflow2013`.`users`.`Reputation` = 400) and (`stackoverflow2013`.`users`.`UpVotes` > 1))",
"cost_info": {
"read_cost": "379.77",
"eval_cost": "39.60",
"prefix_cost": "419.37",
"data_read_per_join": "612K"
},
"used_columns": [
"Id",
"AboutMe",
"Age",
"CreationDate",
"DisplayName",
"DownVotes",
"EmailHash",
"LastAccessDate",
"Location",
"Reputation",
"UpVotes",
"Views",
"WebsiteUrl",
"AccountId"
]
}
}
} |
1 row in set, 1 warning (0.00 sec)
Tôi sẽ phân tích các số liệu bên trên giúp anh em dễ theo dõi nhá
- "query_cost": "419.37" → Đây là tổng COST của câu lệnh này (lưu ý: đây là 1 con số mà MySQL quy đổi ra từ các tài nguyên phải thực hiện như số lượng I/O, CPU, chứ không phải là đơn vị thời gian đâu nhé anh em)
- "index_condition": "((`stackoverflow2013`.`users`.`Reputation` = 400) and (`stackoverflow2013`.`users`.`UpVotes` > 1))", "cost_info": { "read_cost": "379.77", "eval_cost": "39.60", "prefix_cost": "419.37", "data_read_per_join": "612K" } -> Cả cái cụm này cho biết COST của phần việc truy cập vào Index sẽ tiêu tốn thế nào
Trường hợp anh em sử dụng FORMAT = TREE thì kết quả sẽ có định dạng thế này
mysql> EXPLAIN FORMAT=TREE select * from users where reputation = 400 and upvotes > 1;
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| EXPLAIN |
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| -> Index range scan on users using idx_reputation_upvote over (Reputation = 400 AND 1 < UpVotes), with index condition: ((users.Reputation = 400) and (users.UpVotes > 1)) (cost=419 rows=396)
|
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
Ở định dạng này, chúng ta cũng có thể thấy các thông tin
- Cost = 419
- Index Range scan → chiến lược quét trên Index
Ghi chú: Cá nhân tôi thì thích sử dụng FORMAT = TREE và thường sử dụng cách này trong dự án
Nếu như cùng câu lệnh trên như Index idx_reputation_upvote không tồn tại hoặc bị INVISIBLE (ẩn đi khỏi chiến lược thực thi), anh em sẽ thử xem chiến lược lúc này của câu lệnh sẽ có COST ra sao nhé
Để thực hiện cho demo này, tôi sẽ dùng kỹ thuật INVISIBLE Index, trong MySQL thì từ phiên bản MySQL 8.0 mới có nhá anh em
alter table users alter index idx_reputation_upvote invisible
Bây giờ kiểm tra lại chiến lược thực thi của câu lệnh
mysql> EXPLAIN FORMAT=TREE select * from users where reputation = 400 and upvotes > 1;
+------------------------------------------------------------------------------------------------------------------------------------------------+
| EXPLAIN |
+------------------------------------------------------------------------------------------------------------------------------------------------+
| -> Filter: ((users.Reputation = 400) and (users.UpVotes > 1)) (cost=252239 rows=33.7)
-> Table scan on users (cost=252239 rows=2.35e+6)
|
+------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
Nhận xét: Chiến lược thực thi của câu lệnh lúc này là FULL TABLE SCAN (quét toàn bộ các block chứa dữ liệu của bảng). Chiến lược này được thể hiện rõ ràng ở thông số
- Table scan on users
Chiến lược thực thi lúc này có COST = 252239 (tăng hơn 600 lần so với COST khi dùng Index = 419.37 bên trên)
1.2. Giải thuật lựa chọn chiến lược thực thi - Cost Based Optimizer (CBO)
Các Database hiện tại anh em hay sử dụng trong dự án như Oracle, SQL Server, PostgreSQL, và cả MySQL mà chúng ta đang nói tới trong bài này nữa, tất cả chúng đều sử dụng giải thuật lựa chọn chiến lược thực thi dựa trên Cost Based Optimizer (CBO).
Ghi chú: Thật ra thì ở các phiên bản cũ, đời đầu thì mấy ông RDBMS này có 1 cách chọn chiến lược thực thi dựa trên các “Luật”, thuật ngữ gọi là Rule Based Optimizer (RBO), nhưng cái này đã bỏ lâu lắm rồi, nên anh em có thể bỏ qua khỏi đầu nhá.
Nôm na của giải thuật Cost Based Optimizer (CBO) bên trên là Cơ sở dữ liệu sẽ đánh giá tất cả các phương án khả thi của câu lệnh, với mỗi chiến lược thực thi ấy nó sẽ tính ra một cái COST.
Sau đó thì so sánh và chọn ra chiến lược thực thi nào có COST bé nhất.
Nối vậy cũng đồng nghĩa với việc
- Không phải cứ sử dụng Index thì sẽ nhanh hơn FULL TABLE SCAN anh em nhé.
Tôi từng có 1 video chia sẻ về việc khi lựa chọn sai plan (vì CBO và kiến trúc hoạt động của Database), câu lệnh có thể chạy chậm hàng trăm lần.
Như vậy, chúng ta đã hiểu những thứ gì quan trọng và cốt lõi của Query Optimizer trong MySQL.
Bây giờ tôi sẽ cùng anh em tìm hiểu sâu xem khi nâng cấp từ MySQL 5.7 lên MySQL 8.0.x thì đã có những thay đổi gì bên trong và ảnh hưởng tới việc ra quyết định của Query Optimizer nhé.
2. Những cải tiến quan trọng trong Query Optimizer của MySQL 8.0
Tôi luôn khuyến khích các khách hàng sử dụng dịch vụ tư vấn tối ưu của tôi cũng như các học viên của tôi là nếu được hãy nâng cấp lên MySQL 8.0.x, đừng dùng MySQL 5.x nữa, lý do chính vì phiên bản mối có rất nhiều cải tiến quan trọng và hỗ trợ hiệu năng tốt.
2.1. Query Optimizer MySQL 8.0: tối ưu Cost in-memory và cost on-disk
Anh em sắp được xem một vấn đề tồn tại nhiều năm của MySQL 5.7 (và các phiên bản trước đó nữa).
Kiến trúc của MySQL bao gồm 2 phần lớn
- Phần bộ nhớ (Memory) - phần này bản chất là nằm trên RAM của Server
- Phần lưu trữ lâu dài dữ liệu (các Datafile trên Disk).
Trên bộ nhớ thì có nhiều các thành phần khác nhau, nhưng mục tiêu chính là các thông tin sẽ được “Cache” lại tại đây, giảm thiểu việc truy cập vào Disk, do tốc độ và tài nguyên để xử lý trên Disk sẽ “ngốn nhiều hơn, chậm hơn” so với việc thực hiện trên bộ nhớ.
Khi người dùng gửi câu lệnh SQL tới Database MySQL, những dữ liệu của câu lệnh ấy có thể đang ở các nơi khác nhau
- Có thể dữ liệu đang nằm trên Disk (và không có trên bộ nhớ, cụ thể là trong vùng Data Buffer).
- Cũng có thể dữ liệu ấy đã có người dùng khác yêu cầu rồi nên đã có sẵn trên bộ nhớ.
Cost của chiến lược thực thi nếu phải đọc dữ liệu trên bộ nhớ sẽ rất khác với Cost của chiến lược thực thi đọc dữ liệu trên Disk.
Tuy nhiên, các phiên bản MySQL 5.7 trở về trước đều giả định rằng tất cả dữ liệu đều nằm trên Disk hết !!!
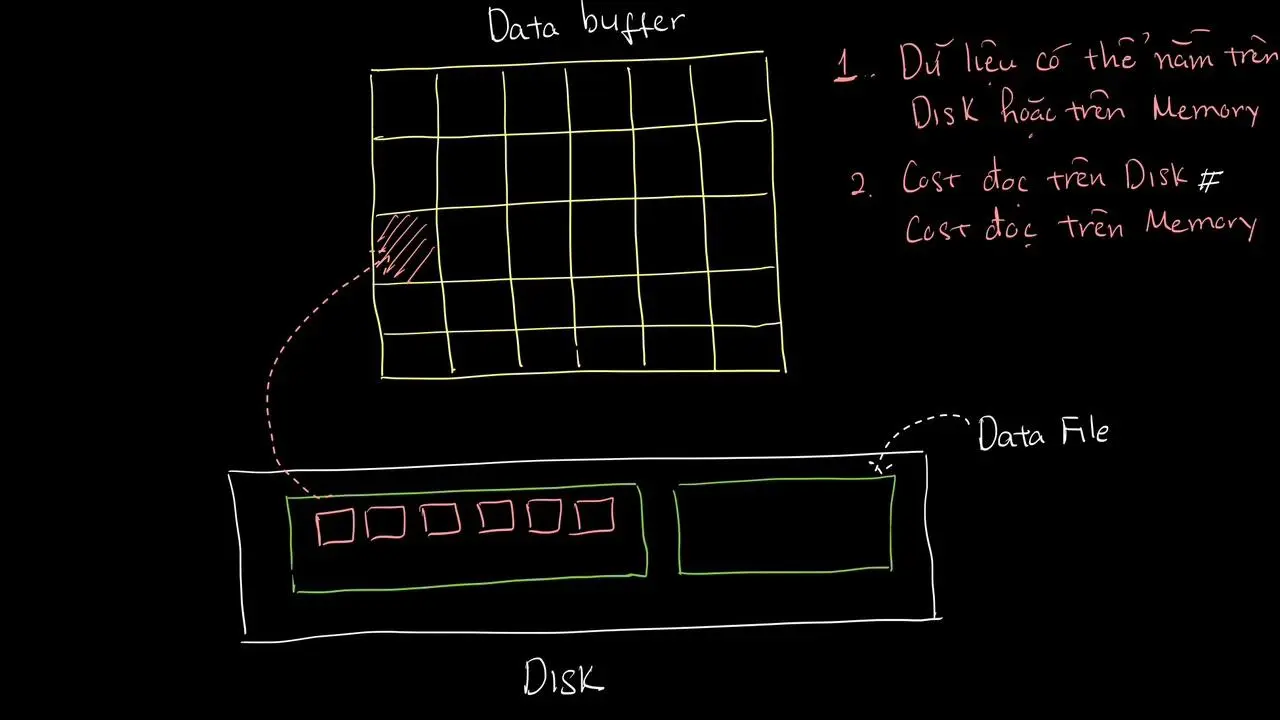
Trong 1 bài viết chia sẻ của MySQL, từng có 1 ví dụ benmark cụ thể như sau
Họ xét 1 câu lệnh SQL
SELECT o_year,
SUM(CASE WHEN nation = 'FRANCE' THEN volume ELSE 0 END) / SUM(volume) AS mkt_share
FROM (
SELECT EXTRACT(YEAR FROM o_orderdate) AS o_year,
l_extendedprice * (1 - l_discount) AS volume, n2.n_name AS nation
FROM part
JOIN lineitem ON p_partkey = l_partkey
JOIN supplier ON s_suppkey = l_suppkey
JOIN orders ON l_orderkey = o_orderkey
JOIN customer ON o_custkey = c_custkey
JOIN nation n1 ON c_nationkey = n1.n_nationkey
JOIN region ON n1.n_regionkey = r_regionkey
JOIN nation n2 ON s_nationkey = n2.n_nationkey
WHERE r_name = 'EUROPE' AND o_orderdate BETWEEN '1995-01-01' AND '1996-12-31'
AND p_type = 'PROMO BRUSHED STEEL'
) AS all_nations GROUP BY o_year ORDER BY o_year;
Ở câu lệnh trên, tồn tại 2 chiến lược thực thi có thể sử dụng
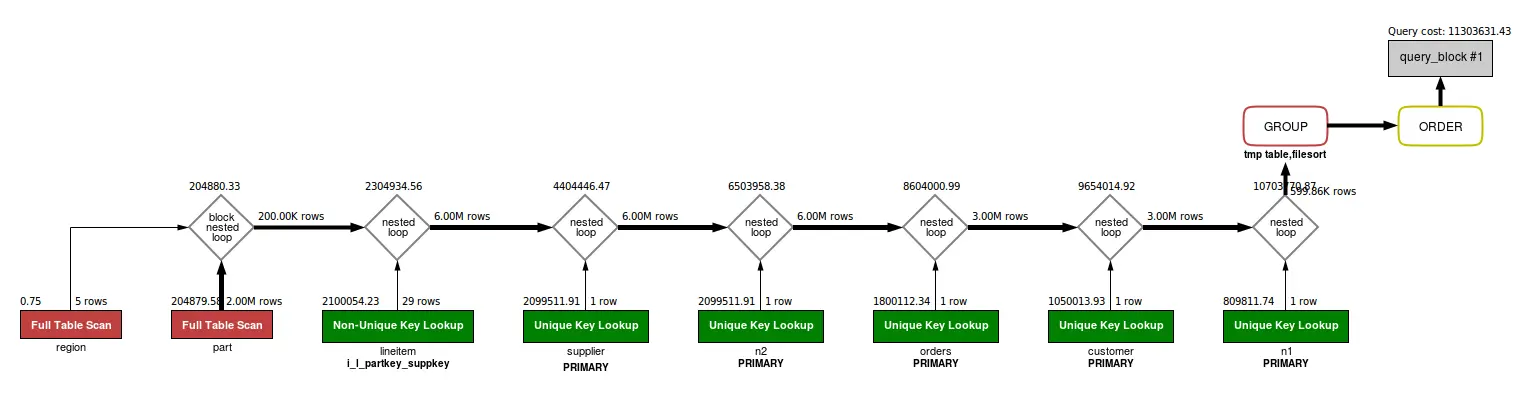
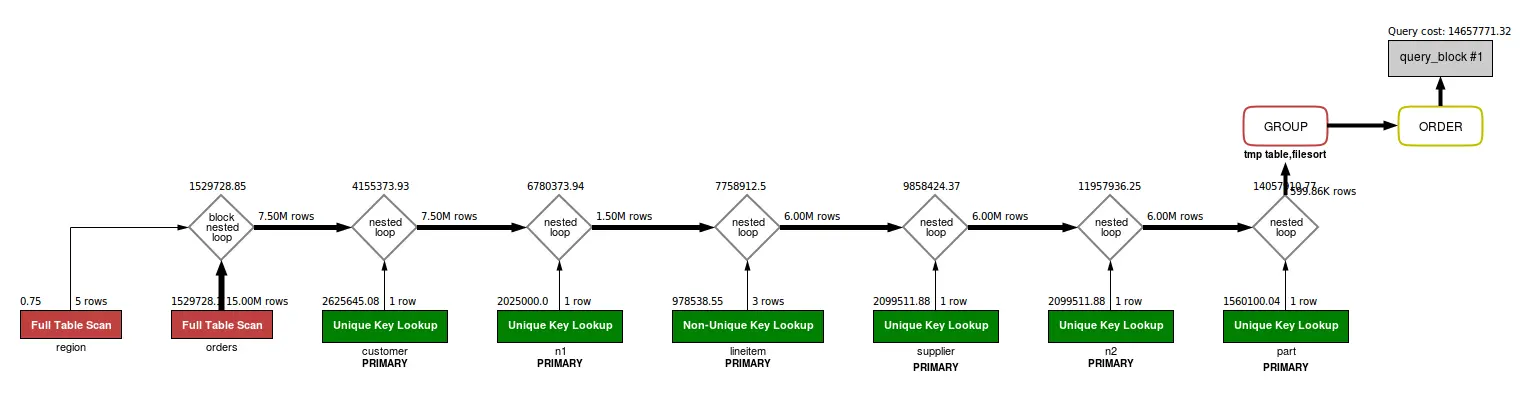
Và đây là kết quả đo lường trong 2 trường hợp: nếu tất cả dữ liệu đều ở trên Memory, và trường hợp khác là nếu tất cả dữ liệu đều ở trên Disk.
Với chiến lược thực thi A
- Nếu tất cả dữ liệu trên Memory: 5.8s
- Nếu tất cả dữ liệu trên Disk: 9 phút 47s
Với chiến lược thực thi B
- Nếu tất cả dữ liệu trên Memory: 77.5s
- Nếu tất cả dữ liệu trên Disk: 3 phút 49s
Như vậy, trong trường hợp Database MySQL có buffer pool lớn, chiến lược thực thi A là tốt nhất, không cần bàn cãi (thời gian nhỏ nhất - 5.8s ).
Còn nếu Database chúng ta có buffer pool nhỏ, thì hệ thống sử dụng phương án B sẽ tốt hơn.
Với cơ sở dữ liệu MySQL 5.7 trở xuống, Query Optimizer sẽ chỉ chọn phương án A hoặc phương án B.
Cụ thể
- Đối với MySQL 5.6, chiến lược thực thi lựa chọn luôn là phương án B
- Đối với MySQL 5.7, chiến lược thực thi lựa chọn luôn là phương án A
Còn trong MySQL 8.0, mọi thứ đã “thông minh” hơn
- Nếu dữ liệu nằm trên Memory, MySQL sẽ tự động lựa chọn phương án A
- Nếu dữ liệu nằm trên Disk, MySQL sẽ chọn phương án ngon hơn là phương án B
Chúc mừng anh em đã nâng cấp MySQL lên 8.0
Cụ thể của việc thay đổi các tham số, cách tính Cost trong MySQL 8.0 so với MySQL 5.7 thì đây nhé anh em:

2.2. MySQL 8.0 Hash Join - cải thiện hiệu năng câu lệnh JOIN
Rất nhiều câu lệnh trong dự án của chúng ta sẽ sử dụng JOIN.
Cách mà chúng ta viết lệnh JOIN và cách Query Optimizer phải xử lý là hoàn toàn khác nhau.
Tôi sẽ cho anh em xem một ví dụ
Trong video anh em đã thấy trước đây MySQL 5.7 chưa hỗ trợ Hash Join (trong khi rất nhiều Database khác đã hỗ trợ từ lâu !)
Đến phiên bản MySQL 8.0.18, Query Optimizer bắt đầu cho phép có thể lựa chọn Hash Join, việc này giúp đạt hiểu quả tốt hơn với các câu lệnh JOIN.
Hãy lưu ý rằng
- Không phải lúc nào Hash Join cũng tốt
- Không phải lúc nào Nested Loop Join cũng tệ
Bản chất ở tôi muốn cho anh em thấy rằng: Bây giờ MySQL 8.0 có nhiều cách thức để xử lý 1 công việc hơn.
Chính vì thế, có nhiều câu lệnh tự nhiên nâng cấp mà nhanh hơn, dù chưa phải viết lại gì, có thể là do lúc đó Query Optimizer đã lựa chọn kiểu Join khác (chọn Hash Join thay vì Nested Loop Join)
3. Kết luận & các tài nguyên bổ trợ
Một số từ khóa quan trọng anh em có thể mang theo sau khi đọc bài này
- Muốn thật sự tối ưu được, từ gốc rễ thì anh em phải hiểu về Query Optimizer (đối với loại Database nào cũng vậy).
- Quá trình nâng cấp phiên bản Database, thứ quan trọng nhât là nâng cấp Query Optimizer (bên cạnh đó có thể các hãng sẽ có các patch fix bug của phiên bản cũ)
- Hiệu năng của câu lệnh phụ thuộc vào chiến lược thực thi
Các bài viết khác anh em nên đọc về tối ưu Database
- Tối ưu SQL thì nên bắt đầu từ đâu (bài quan trọng): Click vào đây để đọc ->